This a brief revisit to the idea of problem decomposition as in one of my previous posts on dual decomposition.
If you have taken a graduate level class on Bayesian Networks, or even an undergraduate class in Artificial Intelligence, then you probably remember the famous "Alarm Problem" below as a first introduction to Bayesian Networks.
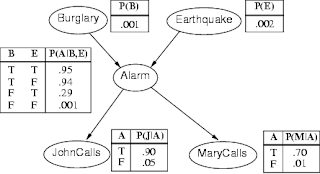
A difficulty arises in working with such networks as one tries to work with the joint probability distribution, $P(B,E,A,J,M)$, where the alphabets stand for the first letter of the
variables depicted in the network above. But the elegant property of Bayesian Networks is that the joint distribution factors multiplicatively into a number of smaller distributions, which are governed by only the relationship between a node and its parents.
For our example network, the joint distribution factors as follows:
\[ P(B,E,A,J,M) = P(J|A)P(M|A)P(A|B,E)P(B)P(E) \] which makes inference much easier to perform because of involvement of the small probability distributions.
It is amazing how the idea of decomposition pervades from relatively basic ideas in Computer Science (such as Merge Sort) to advanced techniques such as Bayesian Networks. I was trying to explain this to the undergraduate class I am a Teaching Assistant for while we were delving into Bayesian Networks for the first time. Just thought I would write a note to myself in my blog, reminding myself of the elegance of the decomposition approach to problem solving.